本篇的主要內容是通過explain逐步分析sql,并通過修改sql語句與建立索引的方式對sql語句進行調優,也可以通過查看日志的方式,了解sql的執行情況,還介紹了MySQL數據庫的行鎖和表鎖。希望對大家有幫助。

一、explain返回列簡介
1、type常用關鍵字
system > const > eq_ref > ref > range > index > all。
- system:表僅有一行,基本用不到;
- const:表最多一行數據配合,主鍵查詢時觸發較多;
- eq_ref:對于每個來自于前面的表的行組合,從該表中讀取一行。這可能是最好的聯接類型,除了const類型;
- ref:對于每個來自于前面的表的行組合,所有有匹配索引值的行將從這張表中讀取;
- range:只檢索給定范圍的行,使用一個索引來選擇行。當使用=、<>、>、>=、<、<=、IS NULL、<=>、BETWEEN或者IN操作符,用常量比較關鍵字列時,可以使用range;
- index:該聯接類型與ALL相同,除了只有索引樹被掃描。這通常比ALL快,因為索引文件通常比數據文件小;
- all:全表掃描;
實際sql優化中,最后達到ref或range級別。
2、Extra常用關鍵字
Using index:只從索引樹中獲取信息,而不需要回表查詢;
Using where:WHERE子句用于限制哪一個行匹配下一個表或發送到客戶。除非你專門從表中索取或檢查所有行,如果Extra值不為Using where并且表聯接類型為ALL或index,查詢可能會有一些錯誤。需要回表查詢。
Using temporary:mysql常建一個臨時表來容納結果,典型情況如查詢包含可以按不同情況列出列的GROUP BY和ORDER BY子句時;
索引原理及explain用法請參照前一篇:MySQL索引原理,explain詳解
二、觸發索引代碼實例
1、建表語句 + 聯合索引
CREATE TABLE `student` ( `id` int(10) NOT NULL, `name` varchar(20) NOT NULL, `age` int(10) NOT NULL, `sex` int(11) DEFAULT NULL, `address` varchar(100) DEFAULT NULL, `phone` varchar(100) DEFAULT NULL, `create_time` timestamp NULL DEFAULT NULL, `update_time` timestamp NULL DEFAULT NULL, `deleted` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `student_union_index` (`name`,`age`,`sex`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
2、使用主鍵查詢
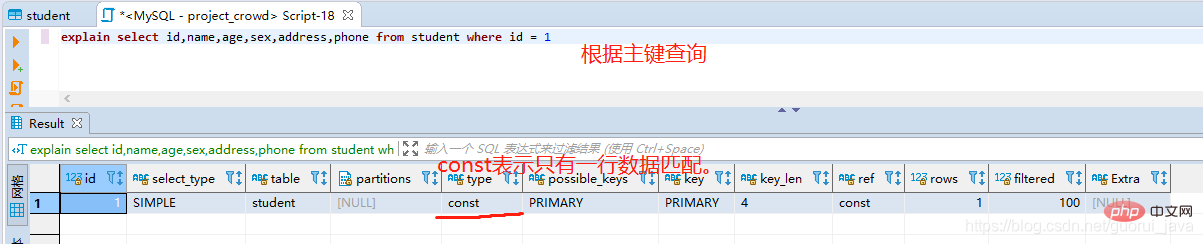
3、使用聯合索引查詢

4、聯合索引,但與索引順序不一致

備注:因為mysql優化器的緣故,與索引順序不一致,也會觸發索引,但實際項目中盡量順序一致。
5、聯合索引,但其中一個條件是 >

6、聯合索引,order by

where和order by一起使用時,不要跨索引列使用。
三、單表sql優化
1、刪除student表中的聯合索引。

2、添加索引
alter table student add index student_union_index(name,age,sex);

優化一點,但效果不是很好,因為type是index類型,extra中依然存在using where。
3、更改索引順序
因為sql的編寫過程
select distinct ... from ... join ... on ... where ... group by ... having ... order by ... limit ...
解析過程
from ... on ... join ... where ... group by ... having ... select distinct ... order by ... limit ...
因此我懷疑是聯合索引建的順序問題,導致觸發索引的效果不好。are you sure?試一下就知道了。
alter table student add index student_union_index2(age,sex,name);
刪除舊的不用的索引:
drop index student_union_index on student
索引改名
ALTER TABLE student RENAME INDEX student_union_index2 TO student_union_index
更改索引順序之后,發現type級別發生了變化,由index變為了range。
range:只檢索給定范圍的行,使用一個索引來選擇行。

備注:in會導致索引失效,所以觸發using where,進而導致回表查詢。
4、去掉in

ref:對于每個來自于前面的表的行組合,所有有匹配索引值的行將從這張表中讀取;
index 提升為ref了,優化到此結束。
5、小結
- 保持索引的定義和使用順序一致性;
- 索引需要逐步優化,不要總想著一口吃成胖子;
- 將含in的范圍查詢,放到where條件的最后,防止索引失效;
四、雙表sql優化
1、建表語句
CREATE TABLE `student` ( `id` int(10) NOT NULL, `name` varchar(20) NOT NULL, `age` int(10) NOT NULL, `sex` int(11) DEFAULT NULL, `address` varchar(100) DEFAULT NULL, `phone` varchar(100) DEFAULT NULL, `create_time` timestamp NULL DEFAULT NULL, `update_time` timestamp NULL DEFAULT NULL, `deleted` int(11) DEFAULT NULL, `teacher_id` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `teacher` ( `id` int(11) DEFAULT NULL, `name` varchar(100) DEFAULT NULL, `course` varchar(100) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
2、左連接查詢
explain select s.name,t.name from student s left join teacher t on s.teacher_id = t.id where t.course = '數學'

上一篇介紹過,聯合查詢時,小表驅動大表。小表也稱為驅動表。其實就相當于雙重for循環,小表就是外循環,第二張表(大表)就是內循環。
雖然最終的循環結果都是一樣的,都是循環一樣的次數,但是對于雙重循環來說,一般建議將數據量小的循環放外層,數據量大的放內層,這是編程語言的優化原則。
再次代碼測試:
student數據:四條
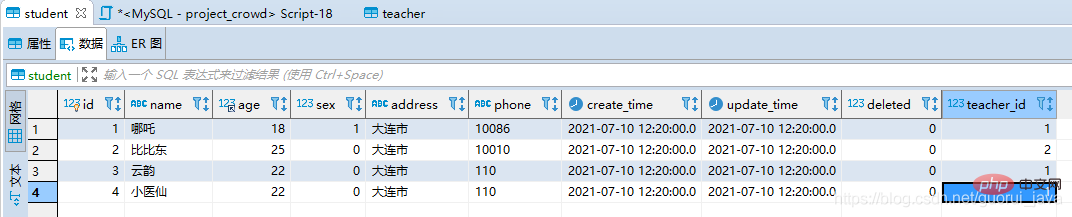
teacher數據:三條

按照理論分析,teacher應該為驅動表。

sql語句應該改為:
explain select teacher.name,student.name from teacher left join student on teacher.id = student.id where teacher.course = '數學'
優化一般是需要索引的,那么此時,索引應該怎么加呢?往哪個表上加索引?
索引的基本理念是:索引要建在經常使用的字段上。
由on teacher.id = student.id可知,teacher表的id字段使用較為頻繁。
left join on,一般給左表加索引;因為是驅動表嘛。

alter table teacher add index teacher_index(id); alter table teacher add index teacher_course(course);

備注:如果extra中出現using join buffer,表明mysql底層覺得sql寫的太差了,mysql加了個緩存,進行優化了。
3、小結
- 小表驅動大表
- 索引建立在經常查詢的字段上
- sql優化,是一種概率層面的優化,是否實際使用了我們的優化,需要通過explain推測。
五、避免索引失效的一些原則
1、復合索引,不要跨列或無序使用(最佳左前綴);
2、符合索引,盡量使用全索引匹配;
3、不要在索引上進行任何操作,例如對索引進行(計算、函數、類型轉換),索引失效;
4、復合索引不能使用不等于(!=或<>)或 is null(is not null),否則索引失效;
5、盡量使用覆蓋索引(using index);
6、like盡量以常量開頭,不要以%開頭,否則索引失效;如果必須使用%name%進行查詢,可以使用覆蓋索引挽救,不用回表查詢時可以觸發索引;
7、盡量不要使用類型轉換,否則索引失效;
8、盡量不要使用or,否則索引失效;
六、一些其他的優化方法
1、exist和in
select name,age from student exist/in (子查詢);
如果主查詢的數據集大,則使用in;
如果子查詢的數據集大,則使用exist;
2、order by 優化
using filesort有兩種算法:雙路排序、雙路排序(根據IO的次數)
MySQL4.1之前,默認使用雙路排序;雙路:掃描兩次磁盤(①從磁盤讀取排序字段,對排序字段進行排序;②獲取其它字段)。
MySQL4.1之后,默認使用單路排序;單路:只讀取一次(全部字段),在buffer中進行排序。但單路排序會有一定的隱患(不一定真的是只有一次IO,有可能多次IO)。
注意:單路排序會比雙路排序占用
