mysql中適合分表的情況:1、數據量過大,正常運維影響業務訪問時,例如對數據庫進行備份需要大量的磁盤IO和網絡IO、對一個表進行DDL修改會鎖住全表、對大表進行訪問與更新出現鎖等待;2、隨著業務發展,需要對某些字段垂直拆分;3、單表中的數據量快速增長,當性能接近瓶頸時,就需要考慮水平切分。

本教程操作環境:windows7系統、mysql8版本、Dell G3電腦。
并不是所有表都需要進行切分,主要還是看數據的增長速度。切分后會在某種程度上提升業務的復雜度,數據庫除了承載數據的存儲和查詢外,協助業務更好的實現需求也是其重要工作之一。
不到萬不得已不用輕易使用分庫分表這個大招,避免"過度設計"和"過早優化"。分庫分表之前,不要為分而分,先盡力去做力所能及的事情,例如:升級硬件、升級網絡、讀寫分離、索引優化等等。當數據量達到單表的瓶頸時候,再考慮分庫分表。
那么mysql中什么時候考慮分表
1、數據量過大,正常運維影響業務訪問
這里說的運維,指:
-
對數據庫備份,如果單表太大,備份時需要大量的磁盤IO和網絡IO。例如1T的數據,網絡傳輸占50MB時候,需要20000秒才能傳輸完畢,整個過程的風險都是比較高的
-
對一個很大的表進行DDL修改時,MySQL會鎖住全表,這個時間會很長,這段時間業務不能訪問此表,影響很大。如果使用pt-online-schema-change,使用過程中會創建觸發器和影子表,也需要很長的時間。在此操作過程中,都算為風險時間。將數據表拆分,總量減少,有助于降低這個風險。
-
大表會經常訪問與更新,就更有可能出現鎖等待。將數據切分,用空間換時間,變相降低訪問壓力
2、隨著業務發展,需要對某些字段垂直拆分
舉個例子,假如項目一開始設計的用戶表如下:

在項目初始階段,這種設計是滿足簡單的業務需求的,也方便快速迭代開發。而當業務快速發展時,用戶量從10w激增到10億,用戶非常的活躍,每次登錄會更新 last_login_name 字段,使得 user 表被不斷update,壓力很大。而其他字段:id, name, personal_info 是不變的或很少更新的,此時在業務角度,就要將 last_login_time 拆分出去,新建一個 user_time 表。
personal_info 屬性是更新和查詢頻率較低的,并且text字段占據了太多的空間。這時候,就要對此垂直拆分出 user_ext 表了。
3、數據量快速增長
隨著業務的快速發展,單表中的數據量會持續增長,當性能接近瓶頸時,就需要考慮水平切分,做分庫分表了。此時一定要選擇合適的切分規則,提前預估好數據容量
業務案例分析
1、用戶中心業務場景
用戶中心是一個非常常見的業務,主要提供用戶注冊、登錄、查詢/修改等功能,其核心表為:
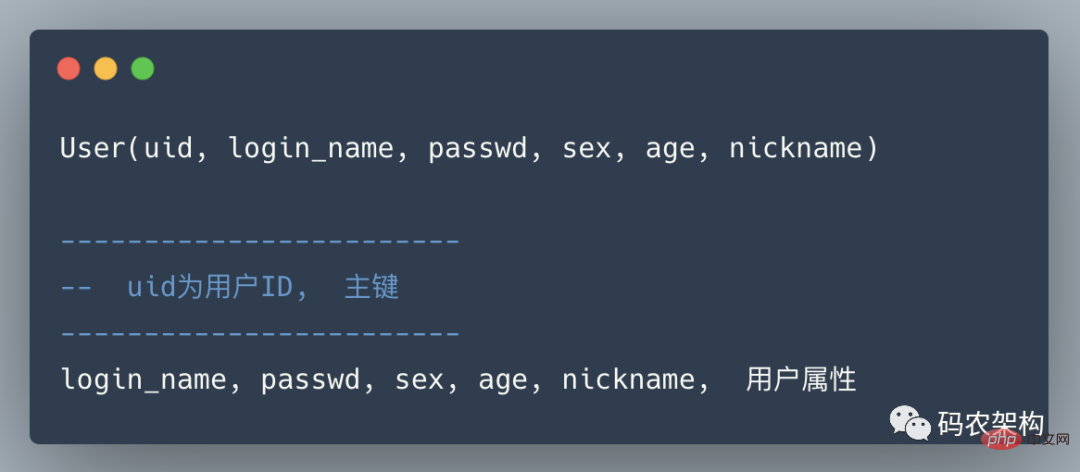
任何脫離業務的架構設計都是耍流氓,在進行分庫分表前,需要對業務場景需求進行梳理:
-
用戶側:前臺訪問,訪問量較大,需要保證高可用和高一致性。主要有兩類需求:
-
-
用戶登錄:通過login_name/phone/email查詢用戶信息,1%請求屬于這種類型
-
用戶信息查詢:登錄之后,通過uid來查詢用戶信息,99%請求屬這種類型
-
-
運營側:后臺訪問,支持運營需求,按照年齡、性別、登陸時間、注冊時間等進行分頁的查詢。是內部系統,訪問量較低,對可用性、一致性的要求不高。
2、水平切分方法
當數據量越來越大時,需要對數據庫進行水平切分,上文描述的切分方法有"根據數值范圍"和"根據數值取模"。
"根據數值范圍":以主鍵uid為劃分依據,按uid的范圍將數據水平切分到多個數據庫上。例如:user-db1存儲uid范圍為0~1000w的數據,user-db2存儲uid范圍為1000w~2000wuid數據。
-
優點是:擴容簡單,如果容量不夠,只要增加新db即可。
-
不足是:請求量不均勻,一般新注冊的用戶活躍度會比較高,所以新的user-db2會比user-db1負載高,導致服務器利用率不平衡
"根據數值取模":也是以主鍵uid為劃分依據,按uid取模的值將數據水平切分到多個數據庫上。例如:user-db1存儲uid取模得1的數據,user-db2存儲uid取模得0的uid數據。
-
優點是:數據量和請求量分布均均勻
-
不足是:擴容麻煩,當容量不夠時,新增加db,需要rehash。需要考慮對數據進行平滑的遷移。
非uid的查詢方法
水平切分后,對于按uid查詢的需求能很好的滿足,可以直接路由到具體數據庫。而按非uid的查詢,例如login_name,就不知道具體該訪問哪個庫了,此時需要遍歷所有庫,性能會降低很多。
對于用戶側,可以采用"建立非uid屬性到uid的映射關系"的方案;對于運營側,可以采用"前臺與后臺分離"的方案。
1、建立非uid屬性到uid的映射關系
-
映射關系
例如:login_name不能直接定位到數據庫,可以建立login_name→uid的映射關系,用索引表或緩存來存儲。當訪問login_name時,先通過映射表查詢出login_name對應的uid,再通過uid定位到具體的庫。
映射表只有兩列,可以承載很多數據,當數據量過大時,也可以對映射表再做水平切分。這類kv格式的索引結構,可以很好的使用cache來優化查詢性能,而且映射關系不會頻繁變更,緩存命中率會很高。
-
基因法
分庫基因:假如通過uid分庫,分為8個庫,采用uid%8的方式進行路由,此時是由uid的最后3bit來決定這行User數據具體落到哪個庫上,那么這3bit可以看為分庫基因。
2、前臺與后臺分離
對于用戶側,主要需求是以單行查詢為主,需要建立login_name/phone/email到uid的映射關系,可以解決這些字段的查詢問題。
而對于運營側,很多批量分頁且條件多樣的查詢,這類查詢計算量大,返回數據量大,對數據庫的性能消耗較高。此時,如果和用戶側公用同一批服務或數據庫,可能因為后臺的少量請求,占用大量數據庫資源,而導致用戶側訪問性能降低或超時。
這類業務最好采用"前臺與后臺分離"的方案,運營側后臺業務抽取獨立的service和db,解決和前臺業務系統的耦合。由于運營側對可用性、一致性的要求不高,可以不訪問實時庫,而是通過binlog異步同步數據到運營庫進行訪問。在數據量很大的情況下,還可以使用ES搜索引擎或Hive來滿足后臺復雜的查詢方式。
【
